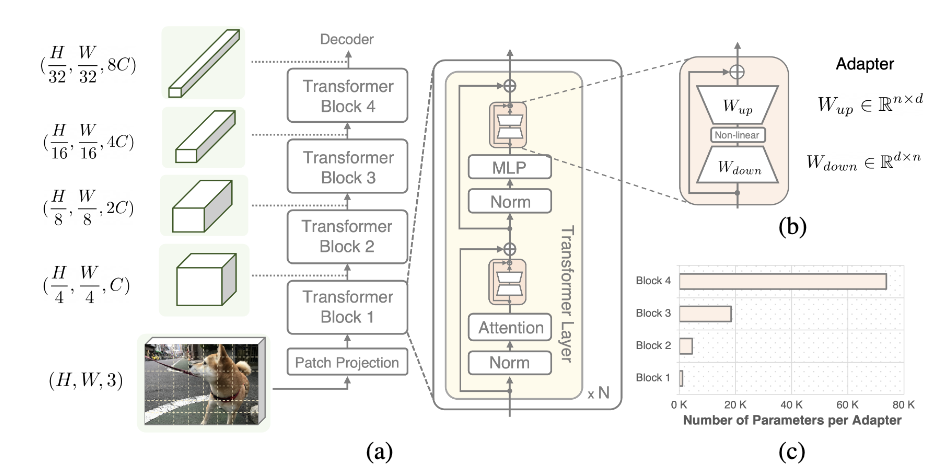
Fig: Illustration of (a) Hierarchical Vision Transformer and (b) Adapter. (c) When applying adapters in a Hierarchical Vision Transformer, the number of parameters grows quadratically with the respect to the block scale.
As the state-of-the-art foundation models grow to billion or even trillion parameter models, individually fine-tuning all parameters of the model wastes significant computational resources. Further, for multi-task models, both fine-tuning and storing separate models for multiple tasks become infeasible on devices with low computation resources. Therefore, we design a novel parameter-efficient method for adaptation to multiple dense vision tasks.
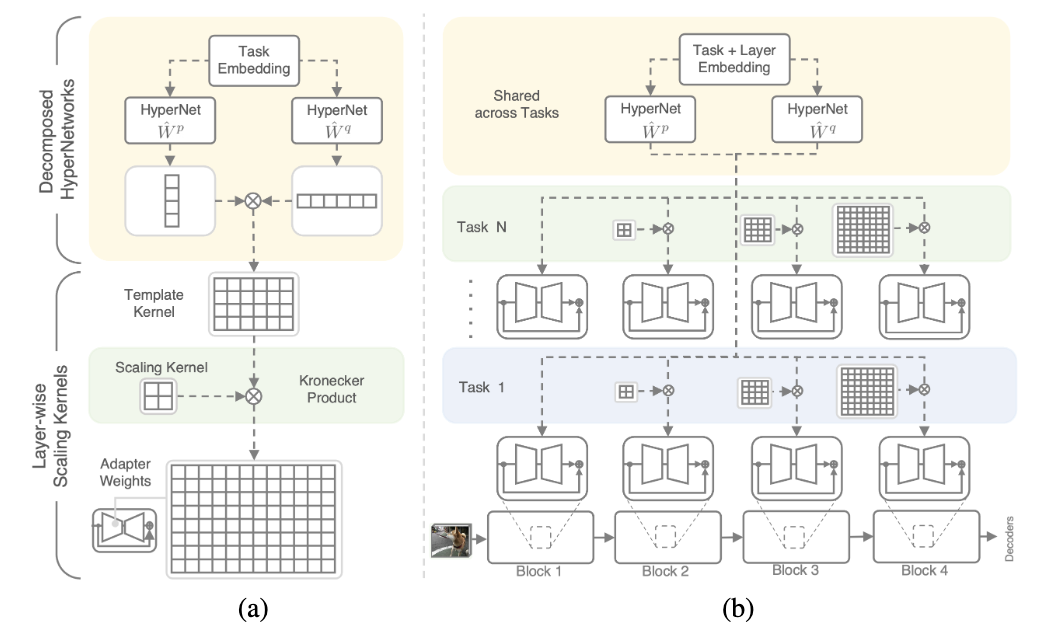
Fig: Illustration of our (a) Polyhistor and (b) Polyhistor-Lite. (a) We apply Decomposed HyperNetworks to reduce the number of training parameters in multi-task adaptation. We introduce Layer-wise Scaling Kernels to efficiently scale up Template Kernels for different scales of adapters. (b) By combining Decomposed HyperNetowrks and Layer-wise Scaling Kernels, our Polyhistor-Lite can efficiently address multi-task adaptation in dense vision tasks.
We propose Polyhistor-Lite, which consist of two main components, Decomposed Lite-HyperNetworks and Layer-wise Scaling Kernels. These two methods reduce the trainable parameters in two aspects respectively, including parameter reduction for hyper-networks in multi-tasking architecture and parameter reduction for adapters used in HVTs For more details of the framework, please refer to our paper.

Polyhistor: Parameter-Efficient Multi-Task Adaptation for Dense Vision Tasks
This project is done partially while Yen-Cheng Liu was interning at Meta.
Yen-Cheng Liu and Zsolt Kira were partly supported by DARPA’s Learning with Less
Labels(LwLL) program under agreement HR0011-18-S-0044, as part of their affiliation with Georgia Tech.